https://mpitutorial.com/tutorials/mpi-scatter-gather-and-allgather/
An introduction to MPI_Scatter
MPI_Bcast sends the same piece of data to all processes while MPI_Scatter sends chunks of an array to different processes.
注意到MPI_Scatter会send chunk给root process
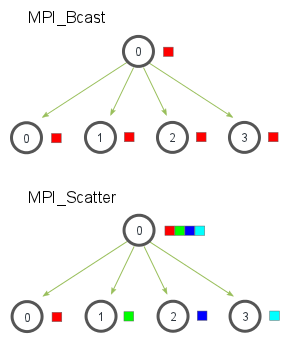
the root process (process zero) contains the entire array of data, MPI_Scatter will copy the appropriate element into the receiving buffer of the process.
MPI_Scatter(
void* send_data,
int send_count,
MPI_Datatype send_datatype,
void* recv_data,
int recv_count,
MPI_Datatype recv_datatype,
int root,
MPI_Comm communicator)
The first parameter, send_data, is an array of data that resides on the root process.
The second and third parameters, send_count and send_datatype, dictate how many elements of a specific MPI Datatype will be sent to each process. If send_count is one and send_datatype is MPI_INT, then process zero gets the first integer of the array, process one gets the second integer, and so on. If send_count is two, then process zero gets the first and second integers, process one gets the third and fourth, and so on. (In practice, send_count is often equal to the number of elements in the array divided by the number of processes. )
(for each receving process) The recv_data parameter is a buffer of data that can hold recv_count elements that have a datatype of recv_datatype.
The last parameters, root and communicator, indicate the root process that is scattering the array of data and the communicator in which the processes reside.
An introduction to MPI_Gather
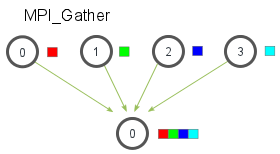
MPI_Gather takes elements from each process and gathers them to the root process. The elements are ordered by the rank of the process from which they were received.
注意到MPI_Scatter会从root process receive chunk
MPI_Gather(
void* send_data,
int send_count,
MPI_Datatype send_datatype,
void* recv_data,
int recv_count,
MPI_Datatype recv_datatype,
int root,
MPI_Comm communicator)
only the root process needs to have a valid receive buffer. All other calling processes can pass NULL for recv_data.
Also, don’t forget that the recv_count parameter is the count of elements received per process, not the total summation of counts from all processes.
Computing average of numbers with MPI_Scatter and MPI_Gather
阅读方式:当做我是0;当做我不是0
注意,MPI_Scatter和MPI_Gather都是collective call,只有一个communicator中所有process都call MPI_Scatter(/MPI_Gather)之后每个process才可能结束MPI_Scatter(/MPI_Gather)的执行
注意,scatter会给root process也分配一个sub数组,看对sub_avgs求平均那里,分母是wolrd_size,即root process也求了一个sub_avg float avg = compute_avg(sub_avgs, world_size);
int main(int argc, char** argv) {
if (argc != 2) {
fprintf(stderr, "Usage: avg num_elements_per_proc\n");
exit(1);
}
int num_elements_per_proc = atoi(argv[1]);
// Seed the random number generator to get different results each time
srand(time(NULL));
MPI_Init(NULL, NULL);
// 进入每个线程私有的部分
int world_rank;
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);
int world_size;
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
// Create a random array of elements on the root process. Its total
// size will be the number of elements per process times the number
// of processes
float *rand_nums = NULL;
if (world_rank == 0) {
rand_nums = create_rand_nums(num_elements_per_proc * world_size);
}
// For each process, create a buffer that will hold a subset of the entire
// array
float *sub_rand_nums = (float *)malloc(sizeof(float) * num_elements_per_proc);
assert(sub_rand_nums != NULL);
// Scatter the random numbers from the root process to all processes in
// the MPI world
MPI_Scatter(rand_nums, num_elements_per_proc, MPI_FLOAT, sub_rand_nums,
num_elements_per_proc, MPI_FLOAT, 0, MPI_COMM_WORLD);
// Compute the average of your subset
float sub_avg = compute_avg(sub_rand_nums, num_elements_per_proc);
// Gather all partial averages down to the root process
float *sub_avgs = NULL;
if (world_rank == 0) {
sub_avgs = (float *)malloc(sizeof(float) * world_size);
assert(sub_avgs != NULL);
}
MPI_Gather(&sub_avg, 1, MPI_FLOAT, sub_avgs, 1, MPI_FLOAT, 0, MPI_COMM_WORLD);
// Now that we have all of the partial averages on the root, compute the
// total average of all numbers. Since we are assuming each process computed
// an average across an equal amount of elements, this computation will
// produce the correct answer.
if (world_rank == 0) {
float avg = compute_avg(sub_avgs, world_size);
printf("Avg of all elements is %f\n", avg);
// Compute the average across the original data for comparison
float original_data_avg =
compute_avg(rand_nums, num_elements_per_proc * world_size);
printf("Avg computed across original data is %f\n", original_data_avg);
}
// Clean up
if (world_rank == 0) {
free(rand_nums);
free(sub_avgs);
}
free(sub_rand_nums);
MPI_Barrier(MPI_COMM_WORLD);
MPI_Finalize();
}
MPI_Allgather and modification of average program
Given a set of elements distributed across all processes, MPI_Allgather will gather all of the elements to all the processes. In the most basic sense, MPI_Allgather is an MPI_Gather followed by an MPI_Bcast. The illustration below shows how data is distributed after a call to MPI_Allgather.
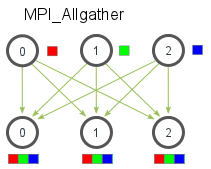
Just like MPI_Gather, the elements from each process are gathered in order of their rank, except this time the elements are gathered to all processes. Pretty easy, right? The function declaration for MPI_Allgather is almost identical to MPI_Gather with the difference that there is no root process in MPI_Allgather.
MPI_Allgather(
void* send_data,
int send_count,
MPI_Datatype send_datatype,
void* recv_data,
int recv_count,
MPI_Datatype recv_datatype,
MPI_Comm communicator)