https://mpitutorial.com/tutorials/mpi-reduce-and-allreduce/
An introduction to reduce
Data reduction involves reducing a set of numbers into a smaller set of numbers via a function. For example, let’s say we have a list of numbers [1, 2, 3, 4, 5]. Reducing this list of numbers with the sum function would produce sum([1, 2, 3, 4, 5]) = 15. Similarly, the multiplication reduction would yield multiply([1, 2, 3, 4, 5]) = 120.
As you might have imagined, it can be very cumbersome to apply reduction functions across a set of distributed numbers. Along with that, it is difficult to efficiently program non-commutative reductions, i.e. reductions that must occur in a set order. Luckily, MPI has a handy function called MPI_Reduce that will handle almost all of the common reductions that a programmer needs to do in a parallel application.
MPI_Reduce
MPI_Reduce takes an array of input elements on each process and returns an array of output elements to the root process. The output elements contain the reduced result.
MPI_Reduce(
void* send_data,
void* recv_data,
int count,
MPI_Datatype datatype,
MPI_Op op,
int root,
MPI_Comm communicator)
The send_data parameter is an array of elements of type datatype that each process wants to reduce. The recv_data is only relevant on the process with a rank of root. The recv_data array contains the reduced result and has a size of sizeof(datatype) * count. (send_data的元素个数也是count,见下方的图片例子)The op parameter is the operation that you wish to apply to your data. MPI contains a set of common reduction operations that can be used. Although custom reduction operations can be defined, it is beyond the scope of this lesson. The reduction operations defined by MPI include:
MPI_MAX- Returns the maximum element.MPI_MIN- Returns the minimum element.MPI_SUM- Sums the elements.MPI_PROD- Multiplies all elements.MPI_LAND- Performs a logical and across the elements.MPI_LOR- Performs a logical or across the elements.MPI_BAND- Performs a bitwise and across the bits of the elements.MPI_BOR- Performs a bitwise or across the bits of the elements.MPI_MAXLOC- Returns the maximum value and the rank of the process that owns it.MPI_MINLOC- Returns the minimum value and the rank of the process that owns it.
Below is an illustration of the communication pattern of MPI_Reduce.
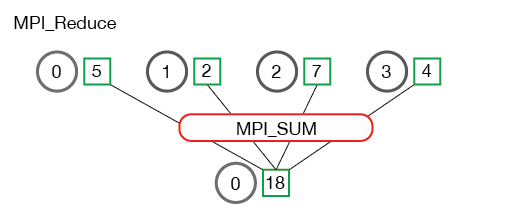
In the above, each process contains one integer. MPI_Reduce is called with a root process of 0 and using MPI_SUM as the reduction operation. The four numbers are summed to the result and stored on the root process.
It is also useful to see what happens when processes contain multiple elements. The illustration below shows reduction of multiple numbers per process.
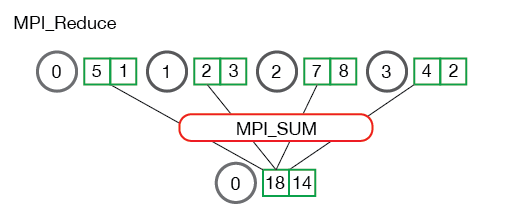
The processes from the above illustration each have two elements. The resulting summation happens on a per-element basis.
example
each process creates random numbers and makes a local_sum calculation. The local_sum is then reduced to the root process using MPI_SUM
int main(int argc, char** argv) {
if (argc != 2) {
fprintf(stderr, "Usage: avg num_elements_per_proc\n");
exit(1);
}
int num_elements_per_proc = atoi(argv[1]);
MPI_Init(NULL, NULL);
int world_rank;
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);
int world_size;
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
// Create a random array of elements on all processes.
srand(time(NULL)*world_rank); // Seed the random number generator to get different results each time for each processor
float *rand_nums = NULL;
rand_nums = create_rand_nums(num_elements_per_proc);
// Sum the numbers locally
float local_sum = 0;
int i;
for (i = 0; i < num_elements_per_proc; i++) {
local_sum += rand_nums[i];
}
// Print the random numbers on each process
printf("Local sum for process %d - %f, avg = %f\n",
world_rank, local_sum, local_sum / num_elements_per_proc);
// Reduce all of the local sums into the global sum
float global_sum;
MPI_Reduce(&local_sum, &global_sum, 1, MPI_FLOAT, MPI_SUM, 0,
MPI_COMM_WORLD);
// Print the result
if (world_rank == 0) {
printf("Total sum = %f, avg = %f\n", global_sum,
global_sum / (world_size * num_elements_per_proc));
}
// Clean up
free(rand_nums);
MPI_Barrier(MPI_COMM_WORLD);
MPI_Finalize();
}
MPI_Allreduce
Many parallel applications will require accessing the reduced results across all processes rather than the root process. MPI_Allreduce will reduce the values and distribute the results to all processes. The function prototype is the following:
MPI_Allreduce(
void* send_data,
void* recv_data,
int count,
MPI_Datatype datatype,
MPI_Op op,
MPI_Comm communicator)
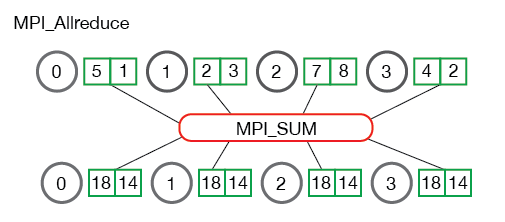
MPI_Allreduce is the equivalent of doing MPI_Reduce followed by an MPI_Bcast
Computing standard deviation with MPI_Allreduce
To find the standard deviation, one must first compute the average of all numbers. After the average is computed, the sums of the squared difference from the mean are computed. The square root of the average of the sums is the final result.
MPI_Allreduce在求标准差时会用到,这是因为求“squared difference from the mean”时每个distributed number都需要知道mean,which is computed after one reduction(若只用MPI_reduce,则只有root process可以得到mean)
int main(int argc, char** argv) {
if (argc != 2) {
fprintf(stderr, "Usage: avg num_elements_per_proc\n");
exit(1);
}
int num_elements_per_proc = atoi(argv[1]);
MPI_Init(NULL, NULL);
int world_rank;
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);
int world_size;
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
// Create a random array of elements on all processes.
srand(time(NULL)*world_rank); // Seed the random number generator of processes uniquely
float *rand_nums = NULL;
rand_nums = create_rand_nums(num_elements_per_proc);
// Sum the numbers locally
float local_sum = 0;
int i;
for (i = 0; i < num_elements_per_proc; i++) {
local_sum += rand_nums[i];
}
// Reduce all of the local sums into the global sum in order to
// calculate the mean
float global_sum;
MPI_Allreduce(&local_sum, &global_sum, 1, MPI_FLOAT, MPI_SUM,
MPI_COMM_WORLD);
// since MPI_Allreduce, now all process has correct global_sum
float mean = global_sum / (num_elements_per_proc * world_size);
// Compute the local sum of the squared differences from the mean
float local_sq_diff = 0;
for (i = 0; i < num_elements_per_proc; i++) {
local_sq_diff += (rand_nums[i] - mean) * (rand_nums[i] - mean);
}
// Reduce the global sum of the squared differences to the root process
// and print off the answer
float global_sq_diff;
MPI_Reduce(&local_sq_diff, &global_sq_diff, 1, MPI_FLOAT, MPI_SUM, 0,
MPI_COMM_WORLD);
// The standard deviation is the square root of the mean of the squared
// differences.
if (world_rank == 0) {
float stddev = sqrt(global_sq_diff /
(num_elements_per_proc * world_size));
printf("Mean - %f, Standard deviation = %f\n", mean, stddev);
}
// Clean up
free(rand_nums);
MPI_Barrier(MPI_COMM_WORLD);
MPI_Finalize();
}
In the above code, each process computes the local_sum of elements and sums them using MPI_Allreduce. After the global sum is available on all processes, the mean is computed so that local_sq_diff can be computed. Once all of the local squared differences are computed, global_sq_diff is found by using MPI_Reduce. The root process can then compute the standard deviation by taking the square root of the mean of the global squared differences.
自定义reduce操作
https://scc.ustc.edu.cn/zlsc/cxyy/200910/MPICH/mpi49.htm
举例
typedef struct {
double real,imag;
} Complex;
/* 用户自定义的函数 */
void myProd(Complex *in, Complex *inout, int *len, MPI_Datatype *dptr)
{
int i;
Complex c;
for (i=0; i < *len; ++i) {
c.real = inout->real*in->real - inout->imag*in->imag;
c.imag = inout->real*in->imag + inout->imag*in->real;
*inout = c;
in++; inout++;
}
}
/* 然后调用它 */
/* 每个进程都有一个100个元素的复数数组 */
Complex a[100], answer[100];
MPI_Op myOp;
MPI_Datatype ctype;
/* 告之MPI复数结构是如何定义的 */
MPI_Type_contiguous(2, MPI_DOUBLE, &ctype);
MPI_Type_commit(&ctype);
/* 生成用户定义的复数乘积操作 */
MPI_Op_create(myProd, True, &myOp);
MPI_Reduce(a, answer, 100, ctype, myOp, root, comm);
/* 这时结果(为100个复数)就已经存放在根进程 */
MPI_OP_CREATE
MPI_OP_CREATE自定义操作,可以用于函数MPI_REDUCE 、MPI_ALLREDUCEMPI_REDUCE_SCATTER和MPI_SCAN中.
MPI_OP_CREATE(function, commute, op)
IN function 用户自定义的函数(函数)
IN commute 可交换则为true,否则为false
OUT op 操作(句柄)
int MPI_Op_create(MPI_User_function *function,int commute,MPI_Op *op)
参数介绍:commute: 用户自定义的操作被认为是可以结合的.如果commute=true,则此操作是可交换且可结合的;如果commute=false,则此操作的顺序是固定地按进程序列号升序方式进行,即从序列号为0的进程开始.
function是用户自定义的函数,必须具备四个参数: invec, inoutvec, len和datatype.
在ANSI C中这个函数的原型是:
typedef void MPI_User_function(void *invec, void *inoutvec,
int *len, MPI_Datatype *datatype);
参数datatype用于控制传送给MPI_REDUCE的数据类型.用户的归约函数应当写成下列方式:
当函数被激活时,令u[0],…,u[len-1]是通信缓冲区中len个由参数invec、len和datatype描述的元素;令v[0],…,v[len- 1]是通信缓冲区中len个由参数inoutvec、len和datatype描述的元素;
当函数返回时,令w[0],…,w[len-1]是通信缓冲区中len个由参数inoutvec、len和datatype描述的元素;此时w[i] = u[i]·v[i] ,i从0到len-1,这里·是function所定义的归约操作.
从非正式的角度来看,我们可以认为invec和inoutvec是函数中长度为len的数组,归约的结果重写了inoutvec的值.每次调用此函数都导致了对这len个元素逐个进行相应的操作,例如:函数将invec[i]·inoutvec[i]的结果返回到inoutvec[i]中,i从0 到count-1,这里·是由此函数执行的归约操作.
tips:
- 参数len可以使MPI_REDUCE不去调用输入缓冲区中的每个元素,也就是说,系统可以有选择地对输入进行处理.在C语言中,为了与Fortran语言兼容,此参数以引用的方式传送.
- 通过内部对数据类型参数datatype的值与已知的、全局句柄进行比较,就可能将一个用户自定义的操作作用于几种不同的数据类型.
通常的数据类型可以传给用户自定义的参数,然而互不相邻的数据类型可能会导致低效率.
在用户自定义的函数中不能调用MPI中的通信函数.当函数出错时可能会调用MPI_ABORT.
下面给出MPI_REDUCE本质的但非高效的实现过程.
if (rank > 0) {
RECV(tempbuf, count, datatype, rank-1,...) /* 从前一个rank接收数据 */
User_reduce(tempbuf, sendbuf, count, datatype) /* 用户定义的函数function */
}
if (rank < groupsize-1) {
SEND(sendbuf, count, datatype, rank+1,...) /* 把结果发送给下一个rank */
}
/* 结果位于进程groupsize-1上,现在将其发送到根进程 */
if (rank == groupsize-1) {
SEND(sendbuf, count, datatype, root, ...)
}
if (rank == root) {
RECV(recvbuf, count, datatype, groupsize-1,...)
}
归约操作顺序地、依次地从进程0计算到进程groupsize-1.这样选择顺序的原因是为了照顾用户自定义的User_reduce函数中有些操作的顺序是不可交换的.更有效的实现方法是采用可结合性的特点或应用对数树形归约法.对于在MPI_OP_CREATE 中 commute为true的情况,还可以利用可交换性的特点,也就是说可以对缓冲区中的一部分数据进行归约操作,这样通信和计算就可以流水执行,即可以传送的数据块的长度len可以小于count.
MPI_OP_FREE
MPI_OP_FREE(op)
IN op 操作(句柄)
int MPI_Op_free(MPI_Op *op)
如要将用户自定义的归约操作撤消,将op设置成MPI_OP_NULL.