https://mpitutorial.com/tutorials/mpi-broadcast-and-collective-communication/
Collective communication and synchronization points
One of the things to remember about collective communication is that it implies a synchronization point among processes. This means that all processes must reach a point in their code before they can all begin executing again.
MPI_Barrier(MPI_Comm communicator)
the function forms a barrier, and no processes in the communicator can pass the barrier until all of them call the function
Want to know how MPI_Barrier is implemented? Sure you do :-) Do you remember the ring program from the sending and receiving tutorial? To refresh your memory, we wrote a program that passed a token around all processes in a ring-like fashion. This type of program is one of the simplest methods to implement a barrier since a token can’t be passed around completely until all processes work together.
Always remember that every collective call you make is synchronized. In other words, if you can’t successfully complete an MPI_Barrier, then you also can’t successfully complete any collective call. If you try to call MPI_Barrier or other collective routines without ensuring all processes in the communicator will also call it, your program will idle
Broadcasting with MPI_Bcast
During a broadcast, one process sends the same data to all processes in a communicator.
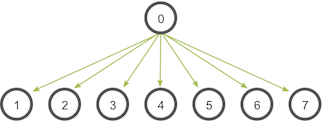
In MPI, broadcasting can be accomplished by using MPI_Bcast. The function prototype looks like this:
MPI_Bcast(
void* data,
int count,
MPI_Datatype datatype,
int root,
MPI_Comm communicator)
Although the root process and receiver processes do different jobs, they all call the same MPI_Bcast function.
- When the root process (in our example, it was process zero) calls
MPI_Bcast, thedatavariable will be sent to all other processes. - When all of the receiver processes call
MPI_Bcast, thedatavariable will be filled in with the data from the root process.
Broadcasting with MPI_Send and MPI_Recv 广播的实现:tree-based
At first, it might seem that MPI_Bcast is just a simple wrapper around MPI_Send and MPI_Recv.
looks like this:
void my_bcast(void* data, int count, MPI_Datatype datatype, int root,
MPI_Comm communicator) {
int world_rank;
MPI_Comm_rank(communicator, &world_rank);
int world_size;
MPI_Comm_size(communicator, &world_size);
if (world_rank == root) {
// If we are the root process, send our data to everyone
int i;
for (i = 0; i < world_size; i++) {
if (i != world_rank) {
MPI_Send(data, count, datatype, i, 0, communicator);
}
}
} else {
// If we are a receiver process, receive the data from the root
MPI_Recv(data, count, datatype, root, 0, communicator,
MPI_STATUS_IGNORE);
}
}
The root process sends the data to everyone else while the others receive from the root process.
very inefficient
A smarter implementation is a tree-based communication algorithm that can use more of the available network links at once.
比如当process0把data传递给了process1之后,process1也可以开始传播
The network utilization doubles at every subsequent stage of the tree communication until all processes have received the data.
(下图含义:每一行表示一个阶段,
第一行:最开始只有0可以发送消息。0发送给了1;
第二行:1收到消息后也开始发送消息,0也继续发送消息。0->2,1->3;
第三行:2和3收到消息后也开始发送消息,0和1也继续发送消息。0->4, 3->6, 1->5, 3->7)
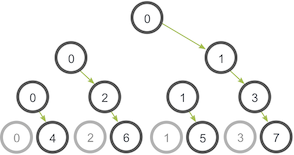
Comparison of MPI_Bcast with MPI_Send and MPI_Recv
MPI_Wtime takes no arguments, and it simply returns a floating-point number of seconds since a set time in the past.
注意更新计时变量前的Barrier,确保所有的process都执行到了MPI_Barrier这一行之后,才让它们更新total_my_bcast_time
// Synchronize before starting timing
MPI_Barrier(MPI_COMM_WORLD);
total_my_bcast_time -= MPI_Wtime();
my_bcast(data, num_elements, MPI_INT, 0, MPI_COMM_WORLD);
// Synchronize again before obtaining final time
MPI_Barrier(MPI_COMM_WORLD);
total_my_bcast_time += MPI_Wtime();
注意在MPI_Init之后初始化的变量是每个process一个copy的,所以total_my_bcast_time是每个process一个copy的,不会有竞争
int main(int argc, char** argv) {
if (argc != 3) {
fprintf(stderr, "Usage: compare_bcast num_elements num_trials\n");
exit(1);
}
int num_elements = atoi(argv[1]);
int num_trials = atoi(argv[2]);
MPI_Init(NULL, NULL);
int world_rank;
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);
double total_my_bcast_time = 0.0;
double total_mpi_bcast_time = 0.0;
int i;
int* data = (int*)malloc(sizeof(int) * num_elements);
assert(data != NULL);
for (i = 0; i < num_trials; i++) {
// Time my_bcast
// Synchronize before starting timing
MPI_Barrier(MPI_COMM_WORLD);
total_my_bcast_time -= MPI_Wtime();
my_bcast(data, num_elements, MPI_INT, 0, MPI_COMM_WORLD);
// Synchronize again before obtaining final time
MPI_Barrier(MPI_COMM_WORLD);
total_my_bcast_time += MPI_Wtime();
// Time MPI_Bcast
MPI_Barrier(MPI_COMM_WORLD);
total_mpi_bcast_time -= MPI_Wtime();
MPI_Bcast(data, num_elements, MPI_INT, 0, MPI_COMM_WORLD);
MPI_Barrier(MPI_COMM_WORLD);
total_mpi_bcast_time += MPI_Wtime();
}
// Print off timing information
if (world_rank == 0) {
printf("Data size = %d, Trials = %d\n", num_elements * (int)sizeof(int),
num_trials);
printf("Avg my_bcast time = %lf\n", total_my_bcast_time / num_trials);
printf("Avg MPI_Bcast time = %lf\n", total_mpi_bcast_time / num_trials);
}
free(data);
MPI_Finalize();
}