https://mpitutorial.com/tutorials/point-to-point-communication-application-random-walk/
The basic problem definition of a random walk is as follows.
Given a Min, Max, and random walker W, make walker W take S random walks of arbitrary length to the right(“a random walk of length/size 6”的意思是,移动6步). If the process goes out of bounds, it wraps back around. W can only move one unit to the right or left at a time.

Parallelization of the random walking problem
splitting the domain across processes
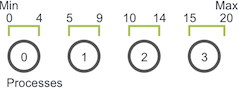
The random walk problem has a one-dimensional domain of size Max - Min + 1 (since Max and Min are inclusive to the walker).
Assuming that walkers can only take integer-sized steps, we can easily partition the domain into near-equal-sized chunks across processes. For example, if Min is 0 and Max is 20 and we have four processes, the domain would be split like this.
if the walker takes a walk of size six on process zero (using the previous domain decomposition), the execution of the walker will go like this:
- The walker starts taking incremental steps. When it hits value four, however, it has reached the end of the bounds of process zero. Process zero now has to communicate the walker to process one.
- Process one receives the walker and continues walking until it has reached its total walk size of six. The walker can then proceed on a new random walk.
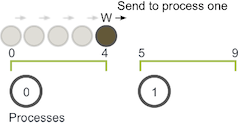
In this example, W only had to be communicated one time from process zero to process one. If W had to take a longer walk, however, it may have needed to be passed through more processes along its path through the domain.
代码逻辑
- Initialize the walkers.(这个意思其实是”出题“)
- Progress the walkers with the
walkfunction. - Send out any walkers in the
outgoing_walkersvector. - Receive new walkers and put them in the
incoming_walkersvector. - Repeat steps two through four until all walkers have finished.
first attempt, may lead to deadlock:
// Find your part of the domain
decompose_domain(domain_size, world_rank, world_size,
&subdomain_start, &subdomain_size);
// Initialize walkers in your subdomain
initialize_walkers(num_walkers_per_proc, max_walk_size,
subdomain_start, subdomain_size,
&incoming_walkers);
while (!all_walkers_finished) { // Determine walker completion later
// Process all incoming walkers
for (int i = 0; i < incoming_walkers.size(); i++) {
walk(&incoming_walkers[i], subdomain_start, subdomain_size,
domain_size, &outgoing_walkers);
}
// Send all outgoing walkers to the next process.
send_outgoing_walkers(&outgoing_walkers, world_rank,
world_size);
// Receive all the new incoming walkers
receive_incoming_walkers(&incoming_walkers, world_rank,
world_size);
}
Deadlock and prevention
the above code will result in a circular chain of MPI_Send calls.
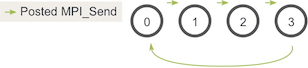
It is worth noting that the above code will actually not deadlock most of the time.
Although
MPI_Sendis a blocking call, the MPI specification says thatMPI_Send blocks until the send buffer can be reclaimed.
This means that
MPI_Sendwill return when the network can buffer the message.If the sends eventually can’t be buffered by the network, they will block until a matching receive is posted.
In our case, there are enough small sends and frequent matching receives to not worry about deadlock, however, a big enough network buffer should never be assumed.
Since we are only focusing on MPI_Send and MPI_Recv in this lesson, the best way to avoid the possible sending and receiving deadlock is to order the messaging such that sends will have matching receives and vice versa.
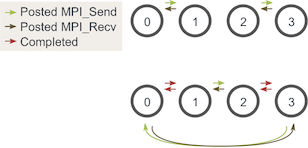
One easy way to do this is to change our loop around such that even-numbered processes send outgoing walkers before receiving walkers and odd-numbered processes do the opposite. Given two stages of execution, the sending and receiving will now look like this:(下图的意思:一行代表一个阶段,但是整个图代表一轮(对应一轮for (int m = 0; m < maximum_sends_recvs; m++)循环中walk完后的处理))
每一阶段(每一行)考察这个阶段开始时三个process的行为:
第一行:0尝试发给1,1尝试从0接收,2尝试发给3,3尝试从2接收:
01解决(0从发送中返回,1从接收中返回);23解决
第二行:0从发送返回后执行接收(即0尝试从3接收),1从接收返回后执行发送(1尝试发送给2),2从发送返回后执行接收(即2尝试从1接收),3从接收返回后执行发送(3尝试发送给0):
03解决;12解决
Note - Executing this with one process can still deadlock. To avoid this, simply don’t perform sends and receives when using one process.
You may be asking, does this still work with an odd number of processes? We can go through a similar diagram again with three processes:
每一阶段(每一行)考察这个阶段开始时三个process的行为:
第一行:0尝试发给1,1尝试从0接收,2尝试发给0:
01解决(0从发送中返回,1从接收中返回);
但是2发给0,这里会block,等待0接收
第二行:0从发送返回后执行接收(即0尝试从2接收),1从接收返回后执行发送(1尝试发送给2),2仍然block在发送给0中:
02解决,2从发送中返回(下一阶段将执行接收),0从接收中返回;
但是1会block在等待2的接收中
第三行:0从接收中返回后本轮的代码结束,1仍然block在发送给2中,2在上一阶段从发送返回后执行接收(2尝试从1接收):
12解决,1从发送中返回,2从接收中返回
至此,都完成了各自的本轮代码
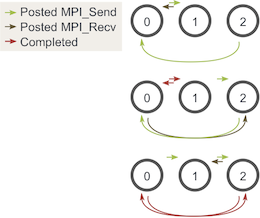
As you can see, at all three stages, there is at least one posted MPI_Send that matches a posted MPI_Recv, so we don’t have to worry about the occurrence of deadlock.
Determining completion of all walkers
cumbersome solution:
have process zero keep track of all of the walkers that have finished and then tell all the other processes when to terminate.
quite cumbersome since each process would have to report any completed walkers to process zero and then also handle different types of incoming messages.
Since we know the maximum distance that any walker can travel and the smallest total size it can travel for each pair of sends and receives (the subdomain size), we can figure out the maximum amount of sends and receives needed to complete all walkers
// Determine the maximum amount of sends and receives needed to
// complete all walkers
int maximum_sends_recvs =
max_walk_size / (domain_size / world_size) + 1;
for (int m = 0; m < maximum_sends_recvs; m++) {
// Process all incoming walkers
// ...
// Send and receive if you are even and vice versa for odd
// ...
}
code
阅读方法:读main
// Author: Wes Kendall
// Copyright 2011 www.mpitutorial.com
// This code is provided freely with the tutorials on mpitutorial.com. Feel
// free to modify it for your own use. Any distribution of the code must
// either provide a link to www.mpitutorial.com or keep this header intact.
//
// Example application of random walking using MPI_Send, MPI_Recv, and
// MPI_Probe.
//
#include <iostream>
#include <vector>
#include <cstdlib>
#include <time.h>
#include <mpi.h>
using namespace std;
typedef struct {
int location;
int num_steps_left_in_walk;
} Walker;
void decompose_domain(int domain_size, int world_rank,
int world_size, int* subdomain_start,
int* subdomain_size) {
if (world_size > domain_size) {
// Don't worry about this special case. Assume the domain size
// is greater than the world size.
MPI_Abort(MPI_COMM_WORLD, 1);
}
*subdomain_start = domain_size / world_size * world_rank;
*subdomain_size = domain_size / world_size;
if (world_rank == world_size - 1) {
// Give remainder to last process
*subdomain_size += domain_size % world_size;
}
}
void initialize_walkers(int num_walkers_per_proc, int max_walk_size,
int subdomain_start,
vector<Walker>* incoming_walkers) {
Walker walker;
for (int i = 0; i < num_walkers_per_proc; i++) {
// Initialize walkers at the start of the subdomain
walker.location = subdomain_start;
walker.num_steps_left_in_walk =
(rand() / (float)RAND_MAX) * max_walk_size;
incoming_walkers->push_back(walker);
}
}
void walk(Walker* walker, int subdomain_start, int subdomain_size,
int domain_size, vector<Walker>* outgoing_walkers) {
while (walker->num_steps_left_in_walk > 0) {
if (walker->location == subdomain_start + subdomain_size) {
// Take care of the case when the walker is at the end
// of the domain by wrapping it around to the beginning
if (walker->location == domain_size) {
walker->location = 0;
}
outgoing_walkers->push_back(*walker);
break;
} else {
walker->num_steps_left_in_walk--;
walker->location++;
}
}
}
void send_outgoing_walkers(vector<Walker>* outgoing_walkers,
int world_rank, int world_size) {
// Send the data as an array of MPI_BYTEs to the next process.
// The last process sends to process zero.
MPI_Send((void*)outgoing_walkers->data(),
outgoing_walkers->size() * sizeof(Walker), MPI_BYTE,
(world_rank + 1) % world_size, 0, MPI_COMM_WORLD);
// Clear the outgoing walkers list
outgoing_walkers->clear();
}
void receive_incoming_walkers(vector<Walker>* incoming_walkers,
int world_rank, int world_size) {
// Probe for new incoming walkers
MPI_Status status;
// Receive from the process before you. If you are process zero,
// receive from the last process
int incoming_rank =
(world_rank == 0) ? world_size - 1 : world_rank - 1;
MPI_Probe(incoming_rank, 0, MPI_COMM_WORLD, &status);
// Resize your incoming walker buffer based on how much data is
// being received
int incoming_walkers_size;
MPI_Get_count(&status, MPI_BYTE, &incoming_walkers_size);
incoming_walkers->resize(incoming_walkers_size / sizeof(Walker));
MPI_Recv((void*)incoming_walkers->data(), incoming_walkers_size,
MPI_BYTE, incoming_rank, 0, MPI_COMM_WORLD,
MPI_STATUS_IGNORE);
}
int main(int argc, char** argv) {
int domain_size;
int max_walk_size;
int num_walkers_per_proc;
if (argc < 4) {
cerr << "Usage: random_walk domain_size max_walk_size "
<< "num_walkers_per_proc" << endl;
exit(1);
}
domain_size = atoi(argv[1]);
max_walk_size = atoi(argv[2]);
num_walkers_per_proc = atoi(argv[3]);
MPI_Init(NULL, NULL);
int world_size;
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
int world_rank;
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);
srand(time(NULL) * world_rank);
int subdomain_start, subdomain_size;
vector<Walker> incoming_walkers, outgoing_walkers;
// Find your part of the domain
decompose_domain(domain_size, world_rank, world_size,
&subdomain_start, &subdomain_size);
// Initialize walkers in your subdomain
initialize_walkers(num_walkers_per_proc, max_walk_size, subdomain_start,
&incoming_walkers);
cout << "Process " << world_rank << " initiated " << num_walkers_per_proc
<< " walkers in subdomain " << subdomain_start << " - "
<< subdomain_start + subdomain_size - 1 << endl;
// Determine the maximum amount of sends and receives needed to
// complete all walkers
int maximum_sends_recvs = max_walk_size / (domain_size / world_size) + 1;
for (int m = 0; m < maximum_sends_recvs; m++) {
// Process all incoming walkers
for (int i = 0; i < incoming_walkers.size(); i++) {
walk(&incoming_walkers[i], subdomain_start, subdomain_size,
domain_size, &outgoing_walkers);
}
cout << "Process " << world_rank << " sending " << outgoing_walkers.size()
<< " outgoing walkers to process " << (world_rank + 1) % world_size
<< endl;
if (world_rank % 2 == 0) {
// Send all outgoing walkers to the next process.
send_outgoing_walkers(&outgoing_walkers, world_rank,
world_size);
// Receive all the new incoming walkers
receive_incoming_walkers(&incoming_walkers, world_rank,
world_size);
} else {
// Receive all the new incoming walkers
receive_incoming_walkers(&incoming_walkers, world_rank,
world_size);
// Send all outgoing walkers to the next process.
send_outgoing_walkers(&outgoing_walkers, world_rank,
world_size);
}
cout << "Process " << world_rank << " received " << incoming_walkers.size()
<< " incoming walkers" << endl;
}
cout << "Process " << world_rank << " done" << endl;
MPI_Finalize();
return 0;
}