https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#programming-model
overall
- thread hierarchy:将问题划分为线程块block
- Thread blocks are required to execute independently: It must be possible to execute them in any order, in parallel or in series.
- Threads within a block can cooperate by sharing data through some shared memory and by synchronizing their execution to coordinate memory accesses.
- thread num within one block:
- all threads of a block are expected to reside on the same processor core and must share the limited memory resources of that core.
- On current GPUs, a thread block may contain up to 1024 threads.
- 16x16 (256 threads) is a common choice.
- cooperate:
- one can specify synchronization points in the kernel by calling the __syncthreads() intrinsic function; __syncthreads() acts as a barrier at which all threads in the block must wait before any is allowed to proceed.
- Shared Memory gives an example of using shared memory.
- In addition to __syncthreads(), the Cooperative Groups API provides a rich set of thread-synchronization primitives.
- For efficient cooperation, the shared memory is expected to be a low-latency memory near each processor core (much like an L1 cache) and __syncthreads() is expected to be lightweight.
- thread num within one block:
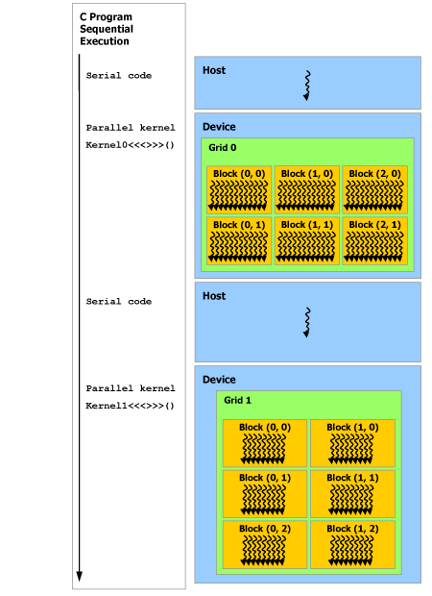
下图:编程模型到硬件的映射
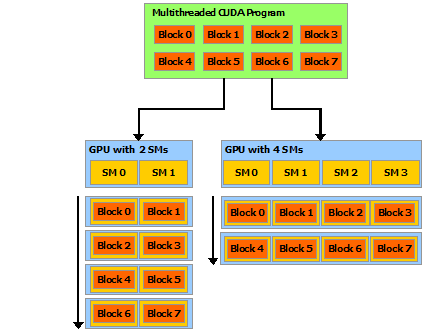
- 一个SM是一个multiprocessor,类似于一个处理器
- block间并行独立因此: a compiled CUDA program can execute on any number of multiprocessors, and only the runtime system needs to know the physical multiprocessor count.
program model
Kernels
defintion and call
- C++ functions
- defined using the
__global__declaration specifier - calling with
<<griddim, blockdim>>- xxdim can be of type
intordim3 - griddim: how the blocks are arranged/indexed
- blockdim: how the threads in a block are arranged/indexed
- elaboration and egs see [Thread Hierarchy](# Thread Hierarchy)
- xxdim can be of type
- defined using the
- when called, are executed N times in parallel by N different CUDA threads (N defined by
<<griddim, blockdim>>). Each thread that executes the kernel is given a unique thread ID that is accessible within the kernel through built-in variables.- “N defined by
<<griddim, blockdim>>“ so a kernel can be executed by multiple equally-shaped thread blocks
- “N defined by
simple eg
adds two vectors A and B of size N and stores the result into vector C:
// Kernel definition
__global__ void VecAdd(float* A, float* B, float* C)
{
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main()
{
...
// Kernel invocation with N threads
VecAdd<<<1, N>>>(A, B, C);
...
}
Thread Hierarchy
index
- built-in variable
threadIdxis a 3-component vector, so that threads can be identified using a one-dimensional, two-dimensional, or three-dimensional thread index, forming a one-dimensional, two-dimensional, or three-dimensional block of threads(指的是 一个block内线程的编排,是block内的相对位置) threadIdxand thread ID:- For a one-dimensional block, they are the same
- for a two-dimensional block of size *(Dx, Dy)*(size: in terms of thread num), the thread ID of a thread of index (x, y) is (x + y Dx)
- for a three-dimensional block of size (Dx, Dy, Dz), the thread ID of a thread of index (x, y, z) is (x + y Dx + z Dx Dy).
- 一个问题的所有block的编排也采用类似的方式,built-in variable
blockIdx - 定位thread:
blockIdx+blockDim定位哪个block,然后在block中threadIdx+threadDim定位哪个thread
eg: structure-in-block
adds two matrices A and B of size NxN and stores the result into matrix C:
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N],
float C[N][N])
{
int i = threadIdx.x;
int j = threadIdx.y;
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel invocation with one block of N * N * 1 threads
int numBlocks = 1;
dim3 threadsPerBlock(N, N);
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}
eg: both-structure-in-block-and-grid
blocks are arranged in 2-dimention
threads in a block are arranged in 2-dimention
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N],
float C[N][N])
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
if (i < N && j < N)
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel invocation
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y); // For simplicity, this example assumes that the number of threads per grid in each dimension is evenly divisible by the number of threads per block in that dimension
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}
Memory Hierarchy
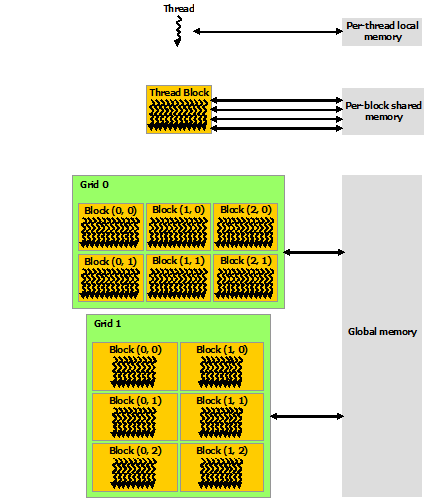
CUDA threads may access data from multiple memory spaces during their execution.
- Each thread has private local memory.
- Each thread block has shared memory visible to all threads of the block and with the same lifetime as the block.
- All threads have access to the same global memory.
- There are also two additional read-only memory spaces accessible by all threads: the constant and texture memory spaces. The global, constant, and texture memory spaces are optimized for different memory usages (see Device Memory Accesses).
- The global, constant, and texture memory spaces are persistent across kernel launches by the same application.
by me: 这样的memory层次划分是和硬件对应的
Heterogeneous Programming
the CUDA programming model assumes that the CUDA threads execute on a physically separate
devicethat operates as a coprocessor to thehostrunning the C++ program.- This is the case, for example, when the kernels execute on a GPU and the rest of the C++ program executes on a CPU.
The CUDA programming model also assumes that both the
hostand thedevicemaintain their own separate memory spaces in DRAM, referred to ashost memoryanddevice memory, respectively.- Therefore, a program manages the global, constant, and texture memory spaces visible to kernels through calls to the CUDA runtime (described in Programming Interface). This includes device memory allocation and deallocation as well as data transfer between host and device memory.
Unified Memory provides managed memory to bridge the host and device memory spaces.
Managed memoryis accessible from all CPUs and GPUs in the system as a single, coherent memory image with a common address space.- This capability enables oversubscription of device memory and can greatly simplify the task of porting applications by eliminating the need to explicitly mirror data on host and device. See Unified Memory Programming for an introduction to Unified Memory.