https://leveldb-handbook.readthedocs.io/zh/latest/sstable.html
SStable文件格式
物理结构
- 一个sstable文件按照固定大小进行块划分,默认每个块的大小为4KiB。
- 每个Block中,除了存储数据以外,还会存储两个额外的辅助字段:
- 压缩类型:说明了Block中存储的数据是否进行了数据压缩,若是,采用了哪种算法进行压缩。leveldb中默认采用Snappy算法进行压缩。
- CRC校验码:校验范围包括数据以及压缩类型。

逻辑结构
将一个sstable分为:
- data block: 用来存储key value数据对;
- filter block: 用来存储一些过滤器相关的数据(布隆过滤器),但是若用户不指定leveldb使用过滤器,leveldb在该block中不会存储任何内容;
- meta Index block: 用来存储filter block的索引信息(索引信息指在该sstable文件中的偏移量以及数据长度);
- index block:index block中用来存储每个data block的索引信息;
- footer: 用来存储meta index block及index block的索引信息;
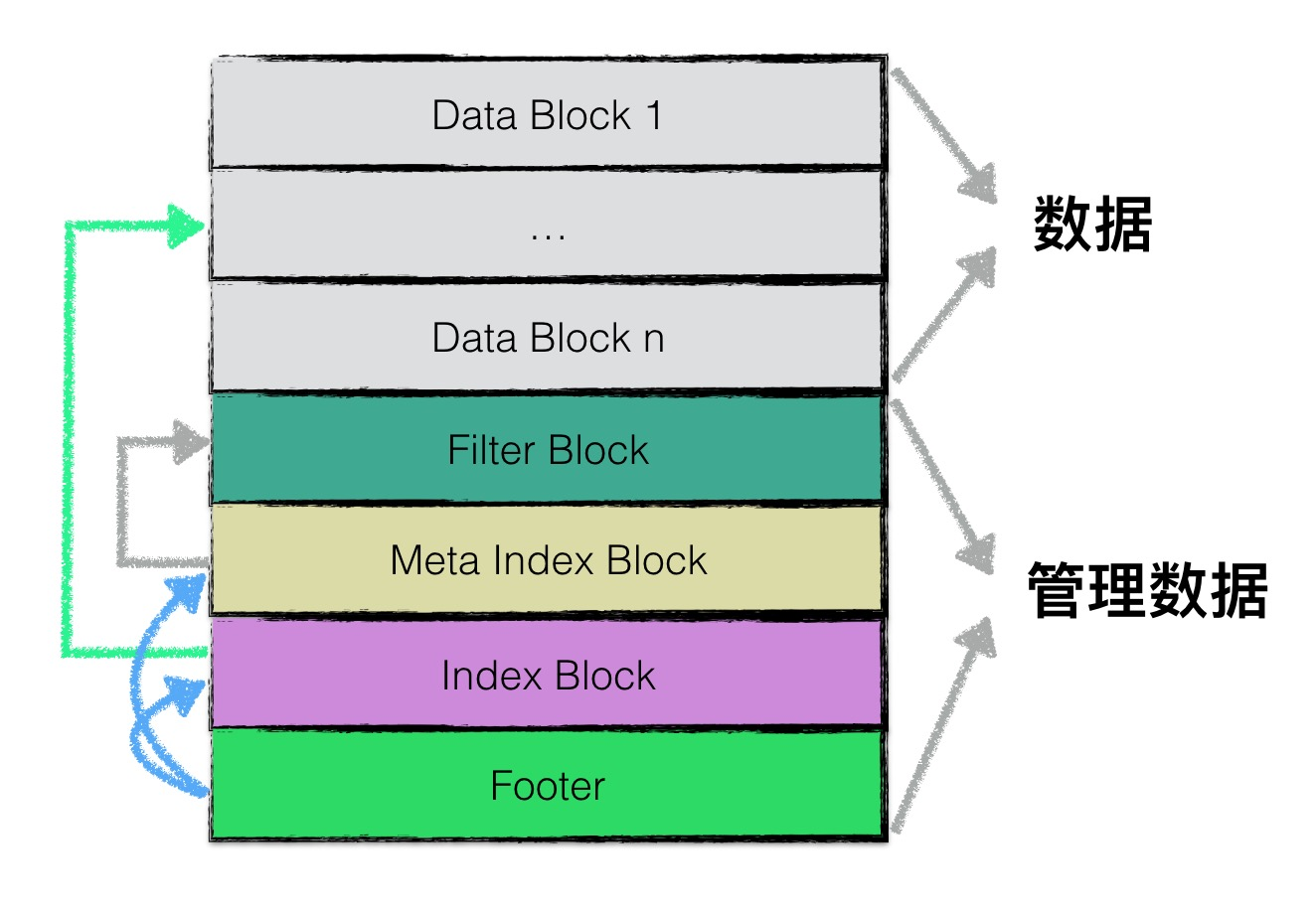
注意,1-4类型的区块,其物理结构都是如1.1节所示,每个区块都会有自己的压缩信息以及CRC校验码信息。
data block结构
一个data block中的数据部分(不包括压缩类型、CRC校验码)按逻辑以下图进行划分:
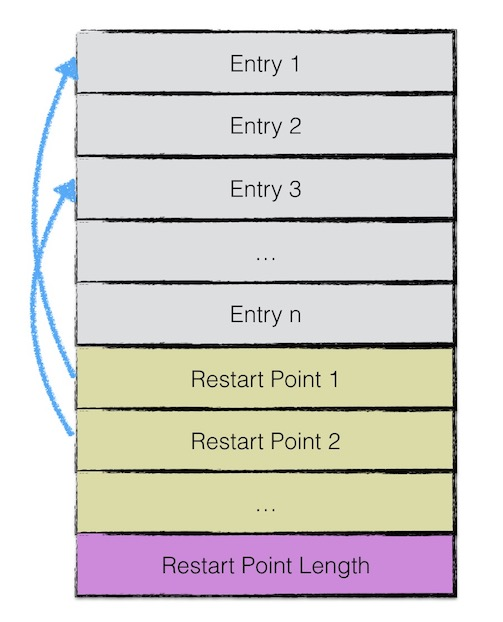
entry存储keyvalue数据
key
- 由于sstable中所有的keyvalue对都是严格按序存储的,为了节省存储空间,leveldb并不会为每一对keyvalue对都存储完整的key值,而是存储与上一个key非共享的部分,避免了key重复内容的存储。
- 每间隔若干个keyvalue对,将为该条记录重新存储一个完整的key。重复该过程(默认间隔值为16),每个重新存储完整key的点称之为Restart point。
加速查找:由于每个Restart point存储的都是完整的key值,因此在sstable中进行数据查找时,可以首先利用restart point点的数据进行键值比较,以便于快速定位目标数据所在的区域;当确定目标数据所在区域时,再依次对区间内所有数据项逐项比较key值,进行细粒度地查找;
entry格式
每个entry的格式如下图所示:

- 与前一条记录key共享部分的长度;
- 与前一条记录key不共享部分的长度;
- value长度;
- 与前一条记录key非共享的内容;
- value内容;
举例
restart_interval=2
entry one : key=deck,value=v1
entry two : key=dock,value=v2
entry three: key=duck,value=v3

三组entry按上图的格式进行存储。值得注意的是restart_interval为2,因此每隔两个entry都会有一条数据作为restart point点的数据项,存储完整key值。因此entry3存储了完整的key。
此外,第一个restart point为0(偏移量),第二个restart point为16,restart point共有两个,因此一个datablock数据段的末尾添加了下图所示的数据:
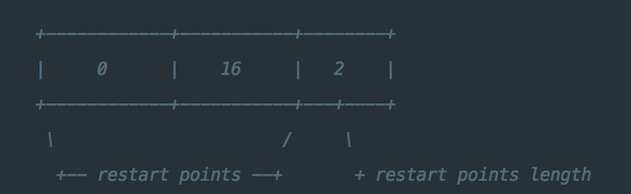
尾部数据记录了每一个restart point的值,以及所有restart point的个数。
SST dump tool
编译sst_dump
参考https://shashangka.com/2020/06/26/rocksdb-administration-and-data-access-tool/
在rocksdb源码顶层目录下
# generate cmake cache
mkdir build
cd build
cmake ..
然后回到rocksdb源码顶层目录下
# config cmake and build
cmake --build ./build --config Debug --target sst_dump
# --build: specify where cmake cache locates
得到sst_dump在<--build指定的目录>/tools下
使用
https://github.com/facebook/rocksdb/wiki/Administration-and-Data-Access-Tool
Printing entries in SST file
./sst_dump --file=/path/to/sst/000829.sst --command=scan --read_num=5
This command will print the first 5 keys in the SST file to the screen. the output may look like this
'Key1' @ 5: 1 => Value1
'Key2' @ 2: 1 => Value2
'Key3' @ 4: 1 => Value3
'Key4' @ 3: 1 => Value4
'Key5' @ 1: 1 => Value5
The output can be interpreted like this
'<key>' @ <sequence number>: <type> => <value>
- Please notice that if your key has non-ascii characters, it will be hard to print it on screen, in this case it’s a good idea to use
--output_hexlike this
./sst_dump --file=/path/to/sst/000829.sst --command=scan --read_num=5 --output_hex
- You can also specify where do you want to start reading from and where do you want to stop by using
--fromand--tolike this
./sst_dump --file=/path/to/sst/000829.sst --command=scan --from="key2" --to="key4"
- You can pass
--fromand--tousing hexadecimal as well by using--input_key_hex
./sst_dump --file=/path/to/sst/000829.sst --command=scan --from="0x6B657932" --to="0x6B657934" --input_key_hex
C