架构
Meta 服务是由 nebula-metad 进程提供的,负责数据管理,例如 Schema 操作、集群管理和用户权限管理等。
所有 nebula-metad 进程构成了基于 Raft 协议的集群,其中一个进程是 leader,其他进程都是 follower。leader 是由多数派选举出来,只有 leader 能够对客户端或其他组件提供服务,其他 follower 作为候补,如果 leader 出现故障,会在所有 follower 中选举出新的 leader
Graph 服务负责处理计算请求,由 nebula-graphd 进程提供。
Storage 服务负责存储数据,由 nebula-storaged 进程提供。
Storage 服务
Nebula Graph 使用 RocksDB 作为本地存储引擎,实现了自己的 KVStore
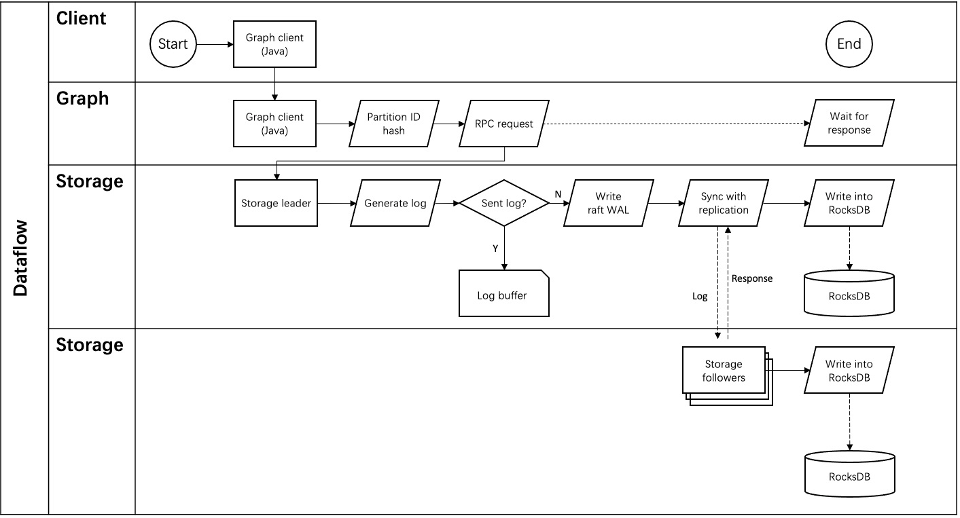
Storage 写入流程
数据存储格式
KV存储
key:点和边的信息
value:点和边的属性信息,将属性信息编码后按顺序存储
- 为了支持在线变更 Schema,在编码属性时,会加入对应的 Schema 版本信息
点
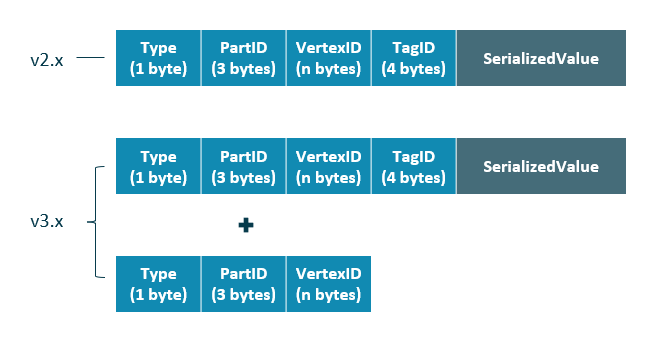
| 字段 | 说明 |
|---|---|
Type |
key 类型。长度为 1 字节。 |
PartID |
数据分片编号。长度为 3 字节。此字段主要用于 Storage 负载均衡(balance)时方便根据前缀扫描整个分片的数据。 |
VertexID |
点 ID。当点 ID 类型为 int 时,长度为 8 字节;当点 ID 类型为 string 时,长度为创建图空间时指定的fixed_string长度。 |
TagID |
点关联的 Tag ID。长度为 4 字节。 |
SerializedValue |
序列化的 value,用于保存点的属性信息。 |
边

| 字段 | 说明 |
|---|---|
Type |
key 类型。长度为 1 字节。 |
PartID |
数据分片编号。长度为 3 字节。此字段主要用于 Storage 负载均衡(balance)时方便根据前缀扫描整个分片的数据。 |
VertexID |
点 ID。前一个VertexID在出边里表示起始点 ID,在入边里表示目的点 ID;后一个VertexID出边里表示目的点 ID,在入边里表示起始点 ID。 |
Edge type |
边的类型。大于 0 表示出边,小于 0 表示入边。长度为 4 字节。 |
Rank |
用来处理两点之间有多个同类型边的情况。用户可以根据自己的需求进行设置,例如存放交易时间、交易流水号等。长度为 8 字节, |
PlaceHolder |
预留字段。长度为 1 字节。 |
SerializedValue |
序列化的 value,用于保存边的属性信息。 |
获取属性
- 由于属性的长度是固定的,查询时可以根据偏移量快速查询。在解码之前,需要先从 Meta 服务中查询具体的 Schema 信息(并缓存)
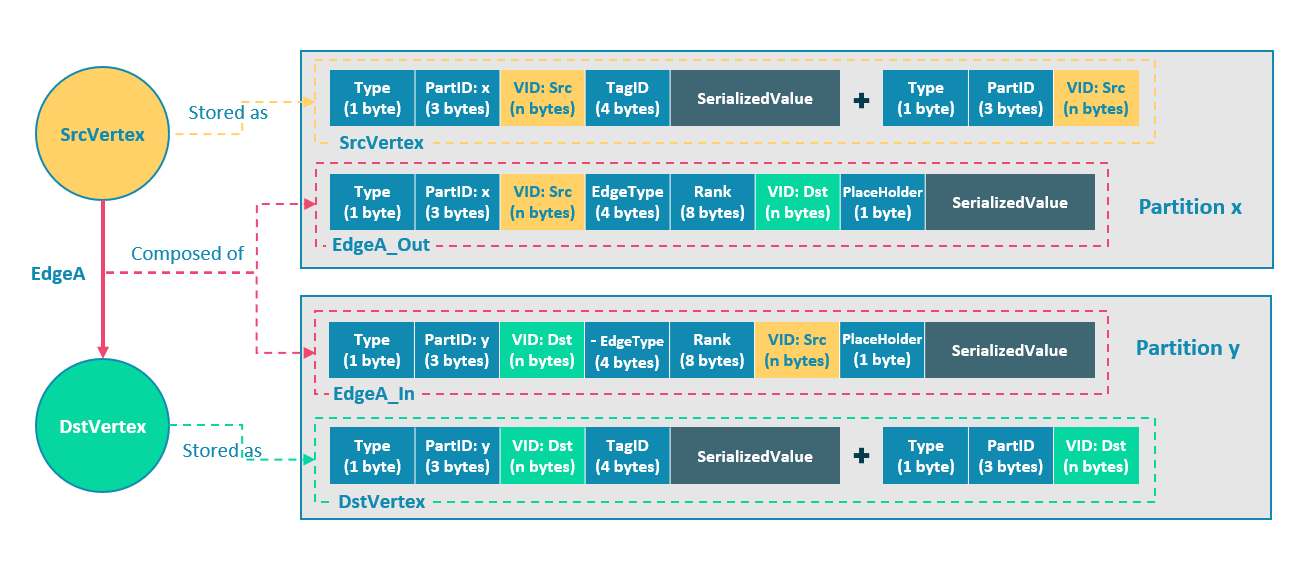
切边
逻辑上的一条边对应着硬盘上的两个键值对:
起点 SrcVertex 通过边 EdgeA 连接目的点 DstVertex,形成路径(SrcVertex)-[EdgeA]->(DstVertex),这两个点和一条边会以 6 个键值对(2(src)+2(dst)+2(edge))的形式保存在存储层的两个不同分片,即 Partition x 和 Partition y 中
服务架构
Store Engine 层
Storage 服务的最底层,是一个单机版本地存储引擎,提供对本地数据的
get、put、scan等操作。相关接口存储在KVStore.h和KVEngine.h文件
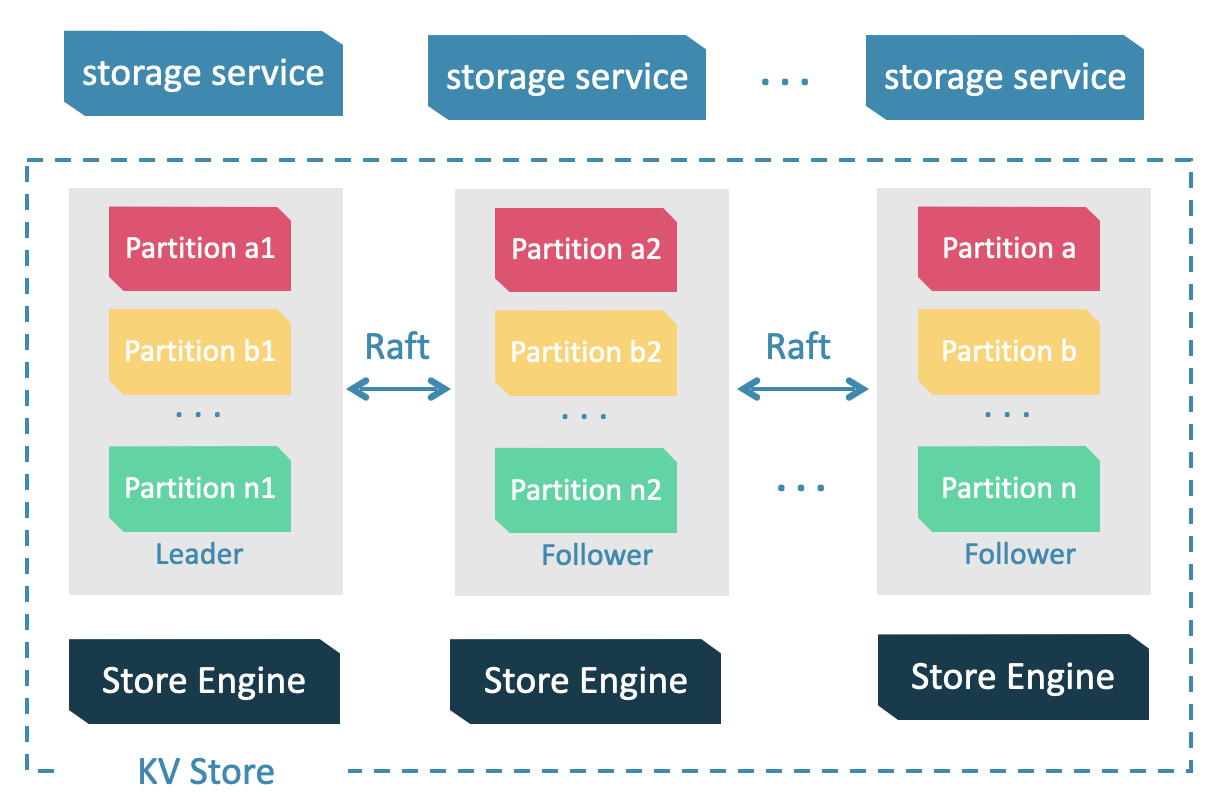
数据分片
- 数据量过大,单机存不下 -> 将图元素切割,并存储在不同逻辑分片(Partition)上
- 分片 ID 和机器地址之间的映射是随机的,不能假定任何两个分片位于同一台机器上
分片算法
- 静态 Hash:对点 VID 进行取模操作(得到分片ID:
pId = vid % numParts + 1),同一个点的所有 Tag、出边和入边信息都会存储到同一个分片
Raft
What is Raft used for?
分布式系统中,同一份数据通常会有多个副本,这样即使少数副本发生故障,系统仍可正常运行。这就需要一定的技术手段来保证多个副本之间的一致性。
通过 保证集群所有节点 log 一致性 来保证。
- 每个分片的所有副本共同组成一个 Raft group,其中一个副本是 leader,其他副本是 follower
缓存
Nebula Graph 自行实现了 Storage 缓存管理指 内存 中缓存外存的内容