用户内存分配和使用的规则(os知识)
堆栈
查看堆栈总大小
每个进程允许的堆栈总大小在linux下可以用ulimit查看 stack size
#查看软极限,单个进程的stack size限制
ulimit -a #或者ulimit -aS
#查看硬极限,软极限的限制
ulimit -aH
堆栈地址增长方向
x86机器上,
- 栈是向下增长的,即入栈是栈顶指针值变小
堆是向上增长的(这个其实无所谓,看操作系统分配堆内存的机制,会分配给哪些内存)
习惯性思考视图:向下方向是地址变小
使用堆or栈的权衡
内存分配消耗:
- 在堆上创建对象需要追踪内存的可用区域。这个算法是由操作系统提供,通常不会是常量时间的。当内存出现大量碎片,或者几乎用到 100% 内存时,这个过程会变得更久。
- 与此相比,栈分配是常量时间的。
分配的大小:
栈的大小是固定的,并且远小于堆的大小。
所以,如果你需要分配很大的对象,或者很多很多小对象,一般而言,堆是更好的选择。如果你分配的对象大小超出栈的大小,通常会抛出一个异常。
局部变量栈分配的规则
(小端法)整形和浮点型:低有效位在低地址,视图是:首地址在“下面”,高位字节到低位字节是”向下走“
比如四字节int型, int a=0x01 02 03 04; 位级表示为0x01 02 03 04的,首字节地址为addr,则内容: addr+3:0x01 addr+2:0x02 addr+1:0x03 addr:0x04数组:数组下标小的在低地址,视图是:首地址在“下面”,idx(数组下标)++给数组赋值是不断“向上走”
比如char数组 char arr[4]={1,2,3,4}; 首字节地址为addr,则内容: addr+3:4 addr+2:3 addr+1:2 addr:1 比如int数组 int arr[2]={0x12345678,0x12345678}; 首字节地址为addr,则内容: addr+7:0x12 addr+6:0x34 addr+5:0x56 addr+4:0x78 addr+3:0x12 addr+2:0x34 addr+1:0x56 addr:0x78 即数组idx++视图是向上走,int元素高位字节到低位字节是向下走
举例:
#include<stdio.h>
int main()
{
int i;
int a[3];
for (i = 0;i <= 11;++i){
a[i] = 0;
printf("%d\n", a[i]);
}
return 0;
}
对应的反汇编objdump -j .text -l -C -S a.out
局部变量i分配在%rbp-4处开始,局部变量数组a分配在%rbp-16处开始,所以其实a[4]是i,所以每次给a[4]=0后即把i=0,这样又重新i从0到4,然后又把i清零,死循环
0000000000400502 <main>:
main():
/home/yuanzhiqiu/tools/c/main.c:3
#include<stdio.h>
int main()
{
400502: 55 push %rbp
400503: 48 89 e5 mov %rsp,%rbp
400506: 48 83 ec 10 sub $0x10,%rsp
/home/yuanzhiqiu/tools/c/main.c:6
int i;
int a[3];
for (i = 0;i <= 11;++i){
40050a: c7 45 fc 00 00 00 00 movl $0x0,-0x4(%rbp) #局部变量i分配在%rbp-4处开始
400511: eb 2b jmp 40053e <main+0x3c>
/home/yuanzhiqiu/tools/c/main.c:7 (discriminator 3)
a[i] = 0;
400513: 8b 45 fc mov -0x4(%rbp),%eax
400516: 48 98 cltq
400518: c7 44 85 f0 00 00 00 movl $0x0,-0x10(%rbp,%rax,4) #局部变量数组a分配在%rbp-16处开始
40051f: 00
/home/yuanzhiqiu/tools/c/main.c:8 (discriminator 3)
printf("%d\n", a[i]);
400520: 8b 45 fc mov -0x4(%rbp),%eax
400523: 48 98 cltq
400525: 8b 44 85 f0 mov -0x10(%rbp,%rax,4),%eax
400529: 89 c6 mov %eax,%esi
40052b: bf d4 05 40 00 mov $0x4005d4,%edi
400530: b8 00 00 00 00 mov $0x0,%eax
400535: e8 c6 fe ff ff callq 400400 <printf@plt>
/home/yuanzhiqiu/tools/c/main.c:6 (discriminator 3)
for (i = 0;i <= 11;++i){
40053a: 83 45 fc 01 addl $0x1,-0x4(%rbp)
/home/yuanzhiqiu/tools/c/main.c:6 (discriminator 1)
40053e: 83 7d fc 0b cmpl $0xb,-0x4(%rbp)
400542: 7e cf jle 400513 <main+0x11>
/home/yuanzhiqiu/tools/c/main.c:10
}
return 0;
400544: b8 00 00 00 00 mov $0x0,%eax
/home/yuanzhiqiu/tools/c/main.c:11
}
400549: c9 leaveq
40054a: c3 retq
40054b: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1)
c++ new delete
可以通过反汇编找到相应的汇编代码
new
new
- 分配内存(堆),获得分配内存的起始地址,这里假设是 0x007da290。
- 是否会对分配的内存的内容进行修改(比如清空)取决于操作系统机制,通常不会改
- 在这一块分配的内存上对类对象进行初始化:调用相应的构造函数
- 返回新分配并构造好的对象的指针,这里 pA 就指向 0x007da290 这块内存,pA 的类型为类 A 对象的指针。
new []
分配内存
对于数组每个元素的内存调用构造函数
(由于delete []时需要知道要析构和释放多少个元素)C++ 会在分配数组空间时多分配 4 个字节,用于保存数组的大小
delete
delete
调用pA 指向对象的析构函数
释放该对象的内存
- 释放内存是否会对被释放的内存的内容进行修改取决于操作系统机制,通常不会改
- 释放这些堆内存之后,操作系统可以把这些堆内存分配给这个进程别的地方了
delete []
- 对每个元素调用析构函数(从数组对象指针前面的 4 个字节中取出数组大小,然后从传入的指针开始析构和释放这么多元素)
- 释放内存(传入的指针是对象指针-4)
c++11 range-for
语法
for (range-declaration : range-expression)
loop-statement
完整语法:
attr(optional) for ( init-statement(optional) range-declaration : range-expression ) loop-statement
编译器生成的代码
range-for语法将产生和下述等价的代码:
{
auto && __range = range-expression;
for (auto __begin = begin_expr, __end = end_expr; __begin != __end; ++__begin)
{
range-declaration = *__begin;
loop_statement
}
}
其中begin_expr 与 end_expr 是迭代对象的迭代器,根据range-expression的类型,取值有:
(1)数组:begin_expr 和 end_expr 分别等于__range和__range + bound;
(2)STL 容器:__range.begin()和__range.end()
(3)其他类型:begin(__range)和end(__range)。编译器将会通过参数类型找到合适的 begin 和 end 函数。
Temporary range expression
If range-expression returns a temporary, its lifetime is extended until the end of the loop, as indicated by binding to the forwarding reference
__range, but beware that the lifetime of any temporary within range-expression is not extended
注意到auto && __range = range-expression在循环之前引用绑定range-expression,循环中是通过__range对迭代对象进行操作,因此如果range-expression返回的是临时对象,则:
- 不会每一轮循环都evaluate一次range-expression得到临时对象,而是循环开始前evaluate一次
- 临时对象的生命周期为整个循环,而不是当轮循环
c++ STL
c++标准中规定,stl要优先考虑性能,为此,其他的容错性以及更多的功能都可以被舍弃掉
观察下面的STL类实现可以发现,没错,栈上的实体是大小在编译期间就可以确定的,所以可以放在栈上,可以增长的存储部分确实是放堆上的
vector
数据成员和数据结构
规则
- 栈上对象:3个迭代器_First、_Last、_End:
- _First指向使用空间的头部,_Last指向使用空间大小(size)的尾部,_End指向使用空间容量(capacity)的尾部
- 堆上存储数据:上面迭代器_First和_End指向的内存范围
所以比如
class A{int x;};
vector<vector> vvs;
vvs这个对象在栈上就三个指针,这三个指针指向堆中的数组,这个数组每个元素都是三个指针的vector对象,这个数组中每个元素的三个指针都指向堆中的一个元素为A的数组
源码
stl_vector.h
template<typename _Tp, typename _Alloc>
struct _Vector_base
{
typedef typename __gnu_cxx::__alloc_traits<_Alloc>::template
rebind<_Tp>::other _Tp_alloc_type;
typedef typename __gnu_cxx::__alloc_traits<_Tp_alloc_type>::pointer
pointer;
struct _Vector_impl //栈上的实际存储:这三个数据成员
: public _Tp_alloc_type
{
pointer _M_start;//容器开始位置
pointer _M_finish;//容器结束位置
pointer _M_end_of_storage;//容器所申请的动态内存最后一个位置的下一个位置
_Vector_impl()
: _Tp_alloc_type(), _M_start(), _M_finish(), _M_end_of_storage() //默认构造函数,不进行堆内存申请
{ }
...
};
public:
typedef _Alloc allocator_type;
...
_Vector_base()
: _M_impl() { }
_Vector_base(size_t __n)
: _M_impl()
{ _M_create_storage(__n); }
...
public:
_Vector_impl _M_impl;
pointer
_M_allocate(size_t __n)
{
typedef __gnu_cxx::__alloc_traits<_Tp_alloc_type> _Tr;
return __n != 0 ? _Tr::allocate(_M_impl, __n) : pointer();
}
void
_M_deallocate(pointer __p, size_t __n)
{
typedef __gnu_cxx::__alloc_traits<_Tp_alloc_type> _Tr;
if (__p)
_Tr::deallocate(_M_impl, __p, __n);
}
private:
void
_M_create_storage(size_t __n)
{
this->_M_impl._M_start = this->_M_allocate(__n);
this->_M_impl._M_finish = this->_M_impl._M_start;
this->_M_impl._M_end_of_storage = this->_M_impl._M_start + __n;
}
};
扩充机制:翻倍找空闲空间,拷贝
规则
vector是动态分配空间,随着元素的不断插入,它会按照自身的一套机制不断扩充自身的容量:按照容器现在容量的一倍进行增长。
vector容器分配的是一块连续的内存空间(堆上),每次容器的增长,并不是在原有连续的内存空间后再进行简单的叠加,而是重新申请一块更大的新内存,并把现有容器中的元素逐个复制过去,然后销毁旧的内存。这时原有指向旧内存空间的迭代器已经失效,所以当操作容器时,迭代器要及时更新
源码
push_back
void
push_back(const value_type& __x)
{
if (this->_M_impl._M_finish != this->_M_impl._M_end_of_storage)
{
_Alloc_traits::construct(this->_M_impl, this->_M_impl._M_finish,
__x);
++this->_M_impl._M_finish;
}
else
_M_realloc_insert(end(), __x);
}
其中_M_realloc_insert:
#if __cplusplus >= 201103L //c++11标准是在2011年3月份发布的,这个表示是c++11及以后
template<typename _Tp, typename _Alloc>
template<typename... _Args>
void
vector<_Tp, _Alloc>::
_M_realloc_insert(iterator __position, _Args&&... __args)
#else
template<typename _Tp, typename _Alloc>
void
vector<_Tp, _Alloc>::
_M_realloc_insert(iterator __position, const _Tp& __x)
#endif
{
//_M_check_len函数功能说明:若传入参数为1:只要没有超出stl规定的最大内存大小,每次返回当前容器大小的双倍,初次返回1
const size_type __len = _M_check_len(size_type(1), "vector::_M_realloc_insert");
const size_type __elems_before = __position - begin();
//_M_allocate函数功能说明:根据传入长度申请内存空间
pointer __new_start(this->_M_allocate(__len));
pointer __new_finish(__new_start);
__try
{
//把x写入相应的位置
_Alloc_traits::construct(this->_M_impl,
__new_start + __elems_before,
#if __cplusplus >= 201103L
std::forward<_Args>(__args)...);
#else
__x);
#endif
__new_finish = pointer();
//这里其实就是把原来数据拷贝到新的内存中来
__new_finish
= std::__uninitialized_move_if_noexcept_a
(this->_M_impl._M_start, __position.base(),
__new_start, _M_get_Tp_allocator());
++__new_finish;
//这里为什么要再调用一次呢,是针对往vector中间插入元素的情况来的
__new_finish
= std::__uninitialized_move_if_noexcept_a
(__position.base(), this->_M_impl._M_finish,
__new_finish, _M_get_Tp_allocator());
}
__catch(...)
{
...;
}
//这里销毁原来的内存并给成员变量赋新值
std::_Destroy(this->_M_impl._M_start, this->_M_impl._M_finish,
_M_get_Tp_allocator());
_M_deallocate(this->_M_impl._M_start,
this->_M_impl._M_end_of_storage
- this->_M_impl._M_start);
this->_M_impl._M_start = __new_start;
this->_M_impl._M_finish = __new_finish;
this->_M_impl._M_end_of_storage = __new_start + __len;
};
建议
所以如果对于一个空vector不断调用push_back,底层是先分配1个元素的内存,然后分配2个元素的内存(如果原来的起始地址开始没有足够大的连续内存,则要申请一块新内存,把原来的内容拷贝过去),4个元素,8个元素…
所以,如果能确定vector必定会被使用且有数据时,我们应该在声明的时候指定元素个数,避免最开始的时候多次申请动态内存消耗资源,进而影响性能
具体接口底层
上面数据结构和规则的应用+一些线性表简单实现
规律:
- 扩充机制:push_back、resize(大小增大的调用)、insert(capacity不够的调用)
- 释放内存:只有析构函数(和c++11及以后的shrink_to_fit)可以主动释放内存,否则只有是扩充的时候发现首地址连续内存不够大,然后换一块会释放原先的内存,其他比如clear\erase\resize等都不会释放内存
具体接口:
- insert:(不够会扩充)把插入位置后面的元素向后移动(拷贝),然后把待插入元素插入到相应的位置
- resize:如果是截断的调用,只是对截断后面的元素调用析构函数,不会有内存分配的变化,也不会释放内存
- clear:对于所有元素调用析构函数,不会有内存分配的变化,也不会释放内存
- delete和erase:会析构被删除元素,会通过拷贝元素来保持连续内存,不会有内存分配的变化,也不会释放内存
- swap:交换三个指针
c++11
c++11以后vector中增加了一些什么内容呢,我们来看看:
- 对于迭代器,增加cbegin系列函数,返回常量迭代器,就是只读迭代器;
- 增加了移动构造函数和移动赋值函数,这一点基本上标准库里面所有类型都增加了;
- 增加公共成员函数shrink_to_fit,允许释放未使用的内存;
- 增加公共成员函数emplace和emplace_back,它支持在指定位置原味构造元素,因为它们是以右值引用的方式传递参数,所以它们相比于push_back这一类的函数,少了一个拷贝的动作
释放vector所有元素存储内存
- swap
vector<int>().swap(v); //想释放v的
v这个vector的三个指针和一个空vector的三个指针进行交换,然后由于这个空vector因为是一个临时变量,它在这行代码结束以后,会自动调用vector的析构函数释放动态内存空间
- c++11以后:shrink_to_fit
先调用clear函数,这样所有元素都变成未使用了;
然后调用shrink_to_fit函数把未使用的部分内存释放掉
list
数据结构:双向链表
有头结点
节点的定义如下:
template<typename T,...>
struct __List_node{
//...
__list_node<T>* prev;
__list_node<T>* next;
T myval;
//...
}
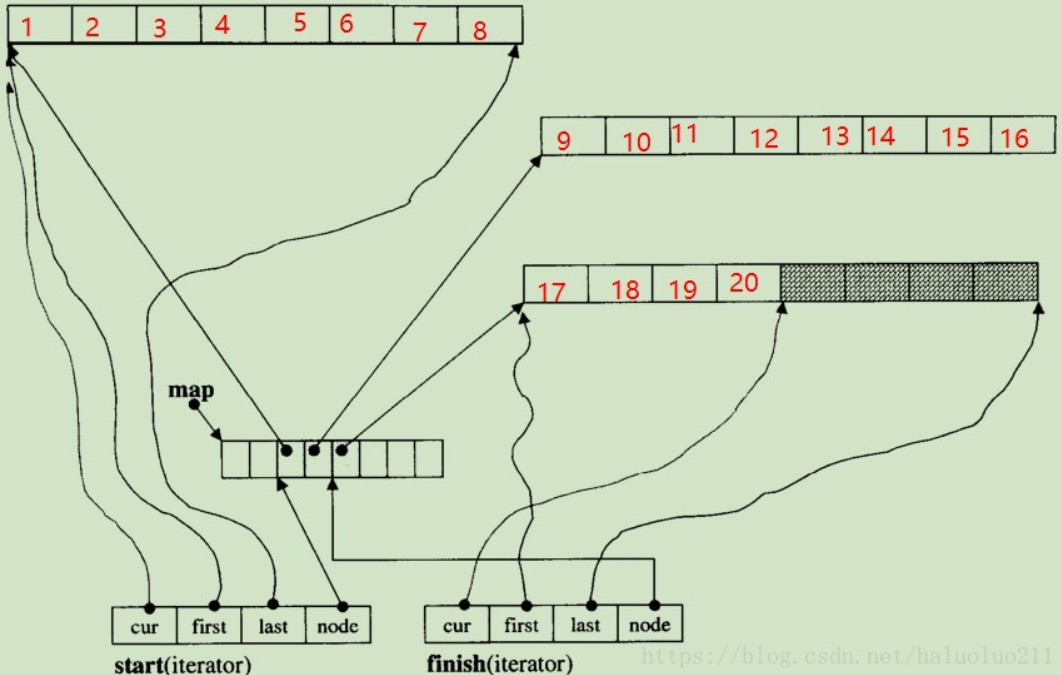
deque
数据结构:首地址数组+多个数组
deque 的元素不一定是相邻存储的:典型实现是
- 多个单独分配的固定大小的相邻元素数组(数组大小:例如 64 位 libstdc++ 上为对象大小的 8 倍空间; 64 位 libc++ 上为对象大小的16 倍或 4096 字节的较大者)
- 有一个元素的 deque :也必须为其分配至少一个内存数组
- 一个数组存储这些空间的首地址(STL中称为map,其中元素称为node)
这表示下标访问必须进行二次指针解引用,与之相比 vector 的下标访问只需要进行一次;迭代器++的时候,可能要换数组,vector只需要迭代器++,而deque还需要从map数组中读取下一个数组的首地址
数据成员
迭代器:三个T*指针(指向当前数组),一个T**指针(指向map数组中当前所在数组对应的首地址节点)
template <class T, class Ref, class Ptr, size_t buff_size>
struct __deque_iterator{
typedef __deque_iterator<T, T&, T*, buff_size> iterator;
typedef __deque_iterator<T, const T&, const T*, buff_size> const_iterator;
static size_t buffer_size() {return __deque_buf_size(buff_size, sizeof(T)); }
typedef T value_type;
typedef size_t size_type;
typedef ptrdiff_t difference_type;
typedef T** map_pointer;
typedef __deque_iterator self;
// 保持与容器的联结
T* cur; // 此迭代器所指之缓冲区中的现行元素
T* first; // 此迭代器所指之缓冲区的头
T* last; // 此迭代器所指之缓冲区的尾(含备用空间)
//由于,指针肯会遇到缓冲区边缘,因此需要跳到下一个缓冲区
//于是需要指向map回去下一个缓冲区地址
map_pointer node; // 指向管控中心
}
deque类:
- 栈:两个迭代器(每个迭代器4个指针,即8个指针),一个T**指针(map数组首地址),一个map_size
- 堆:map数组+多个数组
template<typename T, size_t buff_size = 0>
class deque{
public:
typedef T value_type;
typedef T& reference;
typedef T* pointer;
typedef __deque_iterator<T, T&, T*, buff_size> iterator;
typedef size_t size_type;
typedef ptrdiff_t difference_type;
protected:
typedef pointer* map_pointer;
// 实际的数据存储,分配器
typedef allocator<value_type> dataAllocator;
// map指针分配器
typedef allocator<pointer> mapAllocator;
private: //数据成员
iterator start;
iterator finish;
map_pointer map;
size_type map_size;
}
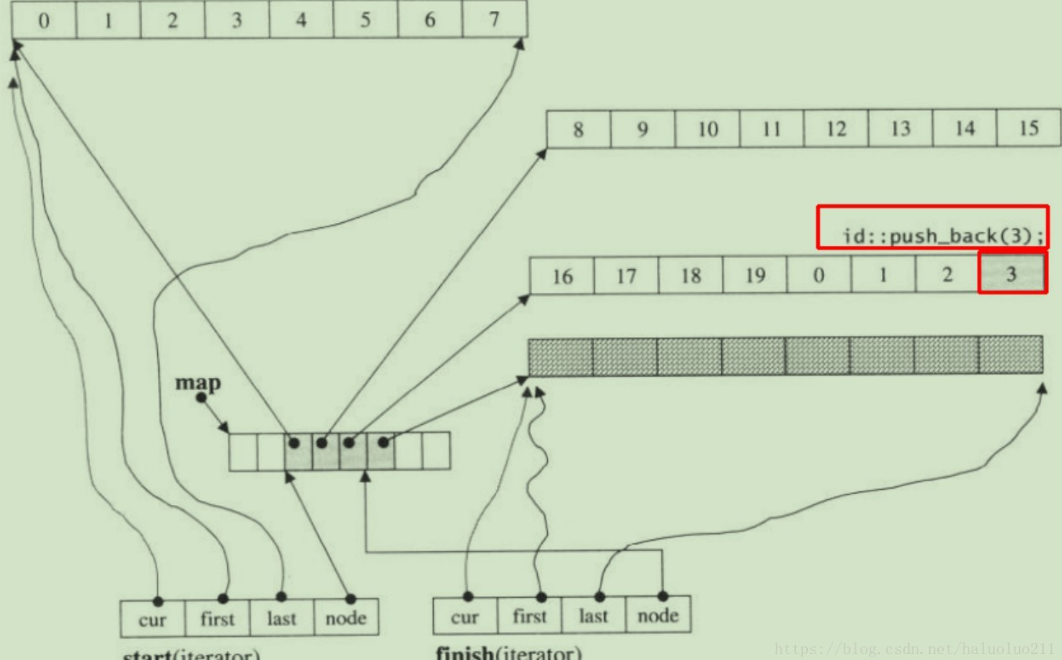
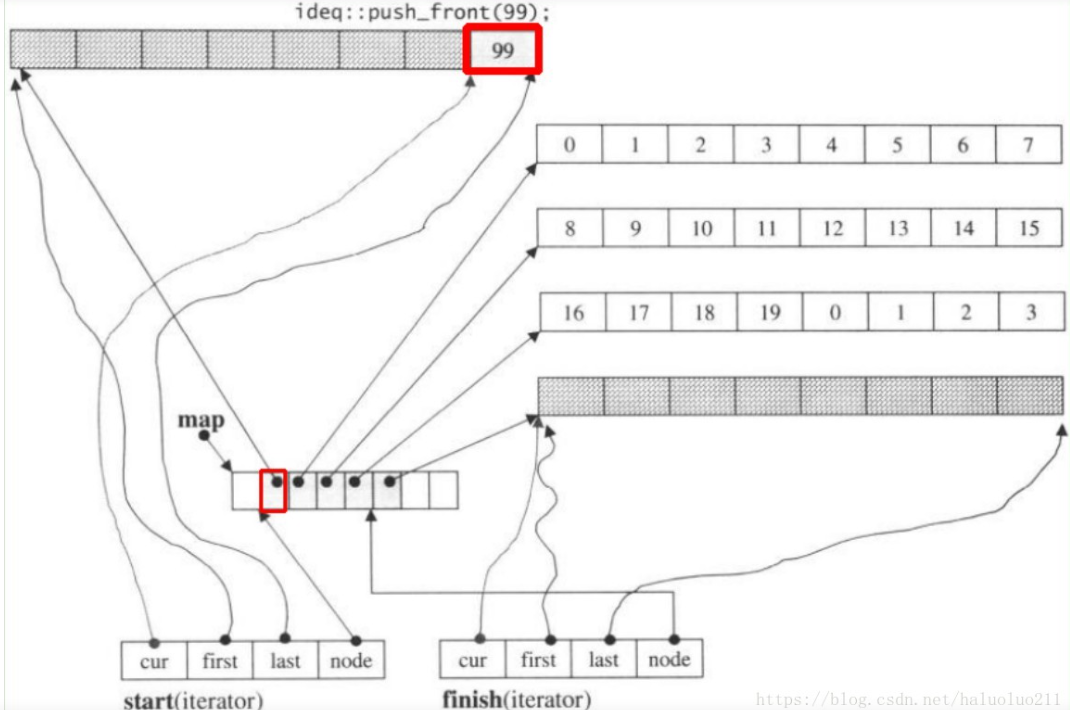
扩充机制:新增固定大小数组,无拷贝
一旦有必要在deque的前端或尾端增加新空间(当当前数组填满最后一个元素,且当前数组是第一个或者最后一个数组时),便配置一段定量连续空间,串接在整个deque的头端或尾端,不需要复制当前的元素到新内存位置
举例:
初始
push_back0 1 2
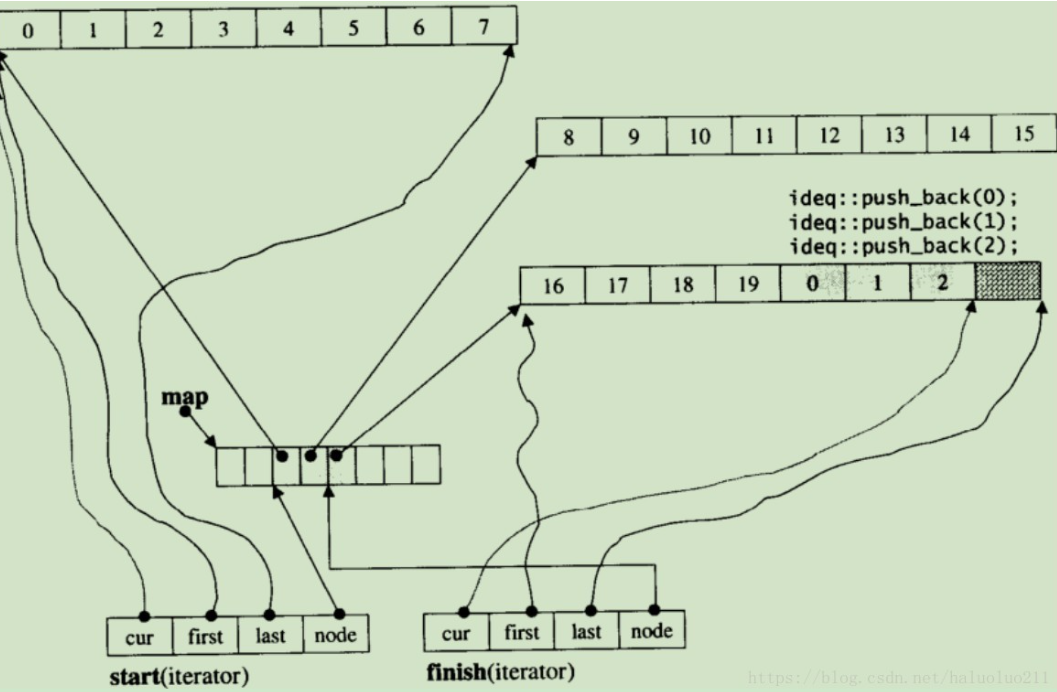
push_back3
push_front99
具体接口
deque源码4(deque元素操作:pop_back、pop_front、clear、erase、insert) - ybf&yyj - 博客园 (cnblogs.com)
pop
- 如果不是当前数组最后一个元素,则只是析构这个待删除元素,正确移动迭代器;
- 如果是最后一个元素,则会释放当前数组,并正确移动迭代器
pop_back
void pop_back(){
if(finish.cur!=finish.first){
//最后缓冲区至少有一个元素
--finish.cur; //调整指针,相当于排除了最后元素 pop_front这里是++
destory(finish.cur); //将最后元素构析
}
else
//最后缓冲区没有任何元素
pop_back_aux(); //这里将进行缓冲区的释放工作
}
//只有当finish.cur==finish.first时才会被调用
template <class T,class Alloc,size_t BufSize>
void deque<T,Alloc,BufSize>::pop_back_aux(){
deallocate_node(finish.first); //释放最后一个缓冲区
finish.set_node(finish.node-1); //调整finish的状态,使指向上一个缓冲区的最后一个元素
finish.cur=finish.last-1;
destory(finish.cur); //将该元素析构
}
clear
存储数组:保留一个存储数组不释放(但是都析构),其余存储数组全部析构和释放
map数组:不释放不析构,只是finish和start迭代器置为相等
template <class T,class Alloc,size_t BufSize>
void deque<T,Alloc,BufSize>::clear(){
//以下针对头尾以外的每一个缓冲区
for(map_pointer node=start.node+1;node<finish.node;++node){
//将缓冲区内的所有元素析构
destory(*node,*node+buff_size());
//释放缓冲区内存
data_allocator::deallocate(*node,buff_size());
}
if(start.node!=finish.node){ //至少有头尾两个缓冲区
destory(start.cur,start.last); //将头缓冲区的目前所有元素析构
destory(finish.first,finish.cur); //将尾缓冲区的目前所有元素析构
//以下释放尾缓冲区,注意,头缓冲区保留
data_allocator::deallocate(finish.first,buffer_size());
}
else //只有一个缓冲区
destory(start.cur,finish.cur); //将此唯一缓冲区内所有元素析构,并保留缓冲区
finish=start; //调整状态
}
erase和insert
- 一个存储数组内部需要保持连续存储,因此会有拷贝(待删除元素或者待插入元素哪边元素少就拷贝哪边)(数组定长比较短,就16或者8)
//清除pos所指向的元素,pos为清除点
iterator erase(iterator pos){
iterator next=pos;
++next;
difference_type index=pos-start; //清除点之前的元素个数
if(index<(size()>>1)){ //如果清除点之前的元素比较少
copy_backward(start,pos,next); //就移动清除点之前的元素
pop_front(); //移动完毕,清除最前一个元素
}
else{ //清除点之后的元素比较少
copy(next,finish,pos); //就移动清除点之后的元素
pop_back(); //移动完毕,清除最后一个元素
}
return start+index;
}
queue和stack:默认底层deque
- queue和stack底层默认是由deque实现
(multi)map,(multi)set
数据结构:红黑树
unordered_(multi)map,unordered_(multi)set
数据结构:开链哈希表
所有无序容器的底层实现:用“开链法”解决数据存储位置发生冲突的哈希表:(图中Pi 表示存储的各个键值对)
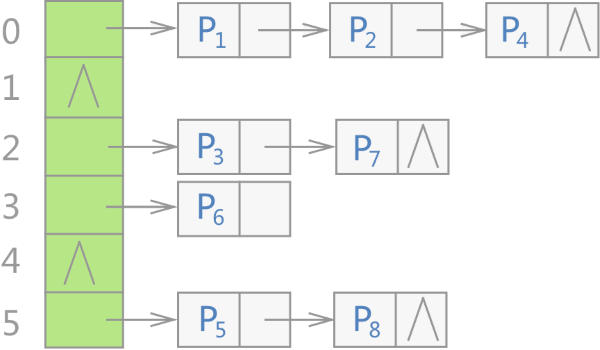
- 一整块连续的存储空间:存储各个链表的头指针,STL 标准库通常选用 vector。
- 各个链表的节点:各键值对
在 C++ STL 标准库中,将图 1 中的各个链表称为桶(bucket),每个桶都有自己的编号(从 0 开始)。
所以如果是用vector来存储链表头指针,
unordered_map栈上对象应该有个vector对象,这个对象有三个指针
然后比如·
class A{int x;};
unordered_map<int, vector> int2vector;
int2vector这个对象在栈上有三个指针,这三个指针指向堆中的数组,这个数组每个元素是链表头指针,链表中每个元素至少是“键+三个指针的vector对象+下一个元素的地址”,其中每个指针都指向堆中的一个元素为A的数组
插入新键值
当有新键值对存储到无序容器中时,整个存储过程分为如下几步:
- 将该键值对中键的值带入设计好的哈希函数,会得到一个哈希值(一个整数,用 H 表示);
- 将 H 和无序容器拥有桶的数量 n 做取模运算(即 H % n),该结果即表示应将此键值对存储到的桶的编号;
- 建立一个新节点存储此键值对,同时将该节点链接到相应编号的桶上。
增加桶数重新哈希
无序容器中,负载因子的计算方法为:
负载因子 = 容器存储的总键值对 / 桶数
默认情况下,无序容器的最大负载因子为 1.0。如果操作无序容器过程中,使得最大负载因子超过了默认值,则容器会自动增加桶数(翻倍式(8、16、32、…)增加(这个翻倍式增长可能是因为链表头指针时是用vector存储的自然导致的)),并重新进行哈希,以此来减小负载因子的值。需要注意的是,此过程会导致容器迭代器失效,但指向单个键值对的引用或者指针仍然有效。
所以,我们在操作无序容器过程中,键值对的存储顺序有时会“莫名”的发生变动。
管理哈希表的成员方法
| 成员方法 | 功能 |
|---|---|
| bucket_count() | 返回当前容器底层存储键值对时,使用桶的数量。 |
比如unordered_map<string, string> umap;初始桶数为8
应用:图邻接表STL选择
邻接表:每个顶点一个邻居列表
考虑每个顶点的邻居用vector存,使用场景为:
初始从文件读取构造的图顶点id从0开始,且是连续的整形id;
后面会不断对图做reduce且不需要”回头“(即不会再需要对reduced图进行恢复):将图规约为仅含当前顶点集的一个子集的导出子图,即实现上(不考虑”假删除“,比如像dancing link那样的链表数据结构,是因为并不需要恢复)表现为将一些顶点的邻居列表清空、将一些顶点的邻居列表中的一些顶点删除,图中实际存在的顶点的id变成可能不是连续的
则整个邻接表用unordered_map还是vector呢?具体来讲:
typedef unsigned VID_TYPE;
unordered_map<VID_TYPE, vector<VID_TYPE>> g_umap;
vector<vector<VID_TYPE>> g_vec;
用g_umap还是g_vec?
我觉得是g_vec:
底层存储
上面举例已经考虑过:
g_vec这个对象在栈上就三个指针,这三个指针指向堆中的数组,这个数组每个元素都是三个指针的vector
对象,这个数组中每个元素的三个指针都指向堆中的一个元素为VID_TYPE的数组; g_umap这个对象在栈上有三个指针,这三个指针指向堆中的数组,这个数组每个元素是链表头指针,链表中每个元素至少是“键+三个指针的vector
对象+下一个元素的地址”,其中每个指针都指向堆中的一个元素为VID_TYPE的数组
考虑g_umap没有出现冲突(可能有增加桶数重新哈希的过程)、每个链表都只有一个元素的最好情况,可以看到g_umap要比g_vec多存储键以及用于链表的指针:顶点数目个指针和键
考虑获取一个顶点的邻居列表
- g_umap:需要用顶点id计算哈希值,然后取模得到头指针数组的下标(头指针数组首指针由g_umap这个栈上对象的数据成员得到),从头指针数组中取出链表首地址,如果链表只有一个元素,则由这个地址找到目标邻居列表vector
的三个指针,返回这个对象(如果有多个元素,要沿着链表一步步找) - g_vec:由顶点id访问元素为vector
的数组(这个数组首指针由g_vec这个栈上对象的数据成员得到),得到目标邻居列表vector 的三个指针,返回这个对象
可以看到,unordered_map由于链表增加了至少一次访存,并且增加了计算哈希值和取模的步骤
unordered_map可以在reduce删除顶点的时候释放掉已经删除的顶点的键值对从而及时释放存储、所以这点优于vector?
这个说法站不住脚:
- 一方面,邻居列表为空的顶点在g_vec中只是占3个指针的空间
- 另一方面,unordered_map删除一个键值对,只是键值对删除了(从链表中删除),桶数目不会变(如果桶数目要缩小的话,所有桶的所有键值对都需要重新哈希,这个开销很大)
[外加]reduce实现
用g_vec,则reduce:原位覆盖+resize+shrink_to_fit:
遍历每个顶点的邻居列表neighbors,一个变量next_new_nbr_idx初始给0,然后如果这个邻居在目标顶点集中,则赋值给neighbors[next_new_nbr_idx++],遍历结束后neighbors.resize(next_new_nbr_idx); neighbors.shrink_to_fit()
resize传入参数若小于当前vector中元素数目,则不会有新的内存分配也不会有释放,只是截断然后析构后面的元素并设置capcity;
然后shrink_to_fit()释放后面的内存
因为在此应用场景下reduce不需要回头,即被从邻居列表中删除掉的顶点不会再重新加入,因此后面邻居列表要占用的内存一定不会比现在释放掉不用的剩下的还多,可以释放掉
[外加]为什么邻居列表不用list呢?
list增删元素很快,且本应用场景中不需要随机访问,依次访问邻居即可,那为什么不用list呢?
我的考虑:因为list底层实现是双向链表,存储的每个元素都多两个指针,在邻居列表存储的实际元素为VID_TYPE仅四个字节的情况下,多存储8个字节的指针,在对于边数为亿级的图感觉不是很合适(10^8个entry,每个12字节,要大约10^9字节,1G)
应用:广度优先搜索的队列用queue还是vector
使用算法
- 用queue:初始时queue中有一个元素(出发点),然后不断从队首取出元素(并删除),并将队首的满足一些性质的邻居加入到队尾
- 用vector:vector中存储每一层:一个level,一个next_level
- 初始时一个元素,然后不断:遍历level中所有元素(不用删除),把当前元素的满足一些性质的邻居加入到next_level中,level遍历完成之后,把next_level移动赋值给level(移动赋值:这样即把next_level的存储数据直接给level(即level的三个指针直接赋值为next_level三个指针的值),level原先的数据会被析构和释放)
我觉得用queue更好
分析内存使用
考虑队列中元素是原始类型,所以没有析构开销
- 用queue:初始时queue中有一个元素(出发点),然后不断从队首取出元素(并删除),并将队首的满足一些性质的邻居加入到队尾
- queue默认用deque实现:
- 初始时会有一个map数组和一个存储数组
- 不断从头部取出和删除元素:由于是从头部删除,则不需要拷贝元素,只有指针移动,以及当当前数组没有元素时将当前数组释放
- 将队首的满足一些性质的邻居加入到队尾:往当前数组尾部加元素,如果满了就申请新的存储数组
- 最后会队列为空,总共申请队列的存储大小是所有入队元素(图BFS的话一个顶点只会入队一次且一定会入队一次,则是顶点数目个元素),在走到empty的时候它们全部都释放完了
- queue默认用deque实现:
- 用vector:vector中存储每一层:一个level,一个next_level
- 初始时一个元素,然后不断:遍历level中所有元素(不用删除),把当前元素的满足一些性质的邻居加入到next_level中,level遍历完成之后,把next_level移动赋值给level(移动赋值:这样即把next_level的存储数据直接给level(即level的三个指针直接赋值为next_level三个指针的值),level原先的数据会被析构和释放)
- 初始时:数组长度为1的数组
- 遍历level:这个只是每次解引用下指针
- 向next_level中加入元素:每次next_level都是从没有元素开始,vector长度以翻倍的方式增长,每次翻倍都需要找新地方、拷贝、析构和释放之前
- 把next_level移动赋值给level:析构和释放level
- 最后队列为空,每次处理一层都会从零开始扩充一个vector(最终大小等于下一层大小),然后会释放这一层
- 初始时一个元素,然后不断:遍历level中所有元素(不用删除),把当前元素的满足一些性质的邻居加入到next_level中,level遍历完成之后,把next_level移动赋值给level(移动赋值:这样即把next_level的存储数据直接给level(即level的三个指针直接赋值为next_level三个指针的值),level原先的数据会被析构和释放)
根据上述粗略的分析,用vector实现多了每一层的从0开始扩张的拷贝开销,其他部分类似,因此用queue更优